How To Read A Wikipedia Dump
If you want a large amount of text data, it’s hard to beat the dump of the English Wikipedia. Even when compressed, the text-only dumps will take up close to 20 gigabytes, and it’ll expand by a factor of 5 to 10 when uncompressed. Effectively handling all of this data can be done on a personal machine, though, due to a combination of two factors – the fact that you can access the data without decompressing it, thanks to the properties of BZ2 files, and the fact that it’s stored as XML data.
I’m going to focus purely on accessing the contents of the pages contained in the September 1, 2020 dump, not any of the multitude of supporting files that come with each dump, including – and especially – the complete page edit histories for each page, which are nearly a terabyte even while compressed. More complete information is on Wikipedia itself, with this page being a good starting point.
The Files
The Wikipedia dump actually consists of two types of files: the files containing the pages, and the index files. These can be downloaded as either one big file for each or a number of smaller files (a few dozen of each for the 2020-09-01 dump).
You’ll note that the files all have “multistream” in their file names. Essentially, the files containing the pages are actually a collection of BZ2 files – “streams” – concatenated together. According to the documentation, each stream contains the text for 100 pages. If you use decompressor like the bzip2 command line tool to decompress the file in one shot, it will return a single file which is the results of the individual decompressed streams concatenated together. There are other tools which can extract content from the files without decompressing the entire thing – R, for instance, can read text directly from a BZ2 file without decompressing it, as most file-reading functions can handle them behind the scenes:
x <- readLines("enwiki-20200901-pages-articles-multistream.xml.bz2", n=5)
x
## [1] "<mediawiki xmlns=\"http://www.mediawiki.org/xml/export-0.10/\" xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\" xsi:schemaLocation=\"http://www.mediawiki.org/xml/export-0.10/ http://www.mediawiki.org/xml/export-0.10.xsd\" version=\"0.10\" xml:lang=\"en\">"
## [2] " <siteinfo>"
## [3] " <sitename>Wikipedia</sitename>"
## [4] " <dbname>enwiki</dbname>"
## [5] " <base>https://en.wikipedia.org/wiki/Main_Page</base>"However, with some knowledge of the contents of the files, it is possible to locate specific streams and only retrieve what you want. The index files for the dump serve as the navigational guide for accessing and retrieving individual streams. As stated in Wikipedia’s documentation of the dumps, each row of the index file consists of three colon-delimited values:
The first field of this index is the number of bytes to seek into the compressed archive pages-articles-multistream.xml.bz2, the second is the article ID, the third the article title.
So the start of the file looks like this:
614:10:AccessibleComputing
614:12:Anarchism
614:13:AfghanistanHistory
614:14:AfghanistanGeography
614:15:AfghanistanPeople
614:18:AfghanistanCommunications
614:19:AfghanistanTransportations
Each stream contains 100 Wikipedia pages, so you can’t isolate single pages. But 100 pages' worth of text from Wikipedia is on the order of megabytes, so any current computer can handle that.
There are a lot of non-article files included in the dump, however, like talk pages or user pages or redirects. In fact, despite only having a little over six million articles, the index file lists over twenty million pages in the dump. If you’re going to try to do something with all of this text, you will want to be careful about exactly what you’re using.
The XML
The tags in the XML for a single page are structured like this:
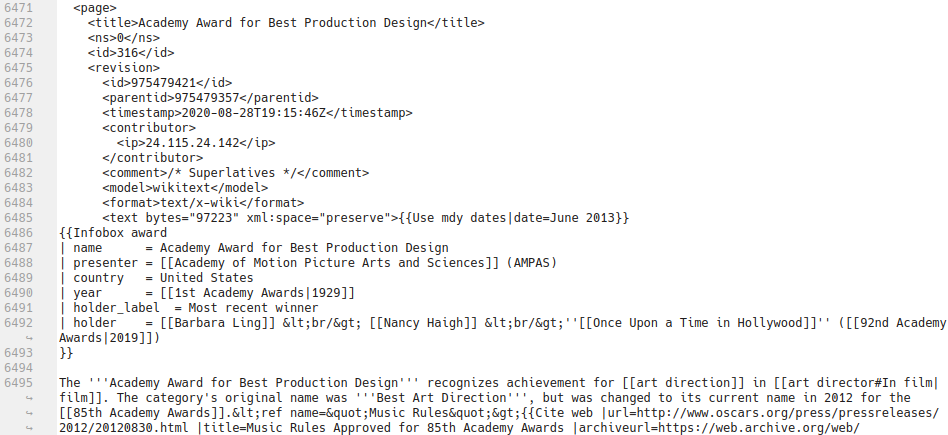
Some tags do not appear on all pages. For instance, the <restrictions> tag deals with pages being locked or in similar states, while the contents of the <contributor> tag depend on whether the most recent edit was done by a logged-in user (in which case <username> and <id> will be present) or not (in which case <ip> will hold the IP address of whoever did the edit).
For the purposes of extracting a page’s text we just need the <text> element under <revision>. The <title> element contains the page title if you’re looking for a specific page.
Extracting A Page
I’ll illustrate the extraction of a single page using Python. To do so, we only need two libraries: bz2 (which is in the standard library already) and BeautifulSoup. (You can substitute the xml from the standard library in place of the latter if you prefer.)
So suppose you were looking to extract the page on microbial fuel cells in the dump. To find it, you need the exact page title and the start and end bytes for that stream. (And I mean exact – there are often redirect pages for alternate capitalizations or formatting of names, and I actually used one for this code at first without realizing it.) The record for that page in the index file is
4233879042:5452870:Microbial fuel cell
Searching a bit farther in the file, we find the record for the first file in the next stream, a redirect page for the town of Wallingford, Connecticut:
4234008653:5453027:Wallingford (CT)
So to extract that stream:
import bz2
from bs4 import BeautifulSoup
DUMP_FILE = "enwiki-20200901-pages-articles-multistream.xml.bz2"
START_BYTE = 4233879042
END_BYTE = 4234008653
decomp = bz2.BZ2Decompressor()
with open(DUMP_FILE, 'rb') as f:
f.seek(START_BYTE)
readback = f.read(END_BYTE - START_BYTE - 1)
page_xml = decomp.decompress(readback).decode()As we’d expect, the stream begins with a <page> tag and ends with a closing </page>:
page_xml[:50]
## " <page>\n <title>Stokell's smelt</title>\n <n"
page_xml[-50:]
## '4bs3rqxoeidnvw67</sha1>\n </revision>\n </page>\n'And we see 100 pages in the extracted stream, also as we would expect:
soup = BeautifulSoup(page_xml, "lxml")
pages = soup.find_all("page")
len(pages)
## 100Finally, you just need to check through the pages to see which one is the article you’re looking for, and then extract its text:
page_titles = [p.find("title").text for p in pages]
page_index = page_titles.index("Microbial fuel cell")
page_index
## 52
microbial_fuel_cell_text = pages[page_index].find("text").text
microbial_fuel_cell_text[:200]
## "A '''microbial fuel cell''' ('''MFC''') is a bio-[[electrochemical]] system<ref>{{cite journal |doi=10.1016/j.desal.2018.01.002 |title=Performance of microbial desalination cell for salt removal and e"You’ll note in the text that there are quite a few bits of formatting, particularly the different kinds of double brackets for internal links and references and such. I’ve had some mixed but generally good luck parsing these with regular expressions, but a full dive into text cleaning Wikipedia pages is beyond the scope of this post, and will probably depend on exactly what you want to do.
Iterating Over Streams
The previous section’s code can handle reading a single stream, but if you want to operate on each in turn, we can just read in the index file and get the start bytes for every stream. Whether you want to – or can – do this all at once or whether you need to build the list of start bytes over a few transactions depends on your computer’s memory. The decompressed index file is almost a gigabyte by itself, and Python’s method of storing strings will make it an order of magnitude larger while it’s in memory.
with open("enwiki-20200901-pages-articles-multistream-index.txt", "r") as f:
index_file = f.readlines()
start_bytes = [int(x.split(":")[0]) for x in index_file]
start_bytes = set(start_bytes) ## to deduplicate the list
start_bytes = list(start_bytes) ## but we want them in a specific order
start_bytes.sort()You’ll need to append the endpoint of the final file size to this list. If you want to make it consistent with the code above, add 1 to it so that it will properly end on the end of the file; otherwise, you’ll want to handle the case of the last stream separately.
import os
file_size = os.path.getsize("enwiki-20200901-pages-articles-multistream.xml.bz2")
start_bytes.append(file_size + 1)From here, you can just loop over the single stream code for each stream. Though it’s probably obvious, it’s worth highlighting that this will be fairly slow. There are about 200,000 streams in the file (20 million pages at 100 pages/stream), and since executing the extraction code on each takes multiple seconds, operating on them one at a time will be very time-consuming.
Final Notes
There are a few other things to note:
- If you’re going to use Python to access the file like I did, I suggest reading the documentation on Python’s
bz2library first. In particular, regard the note in there about needed to use a new decompressor object for each decompression operation. - You can tweak the above code to read multiple streams in one operation, if you want to handle larger batches of text (which you probably do). As long as the portion of the file you’re reading begins and ends with the appropriate start and end bytes, the data can be decompressed just fine.
- An alternate (though, in my view, much less flexible) method would be to retrieve one line of text from the compressed file at a time, keep track of how many closing </page> tags you encounter, and then flush the stored text to a file and start again. Here’s a StackOverflow post that does this with Python.